
On a cold afternoon standing on a bluff overlooking 907F and her Junction Butte packmates, I could hear the wind cross the ridge before I saw it. It slid through the timber, rattled last year’s leaves, and pulled at my coat. If you listen long enough, you begin to notice the spaces between gusts. And, as a linguist, I thought of the underlying pattern in the wind.
What you don’t see is the dance of the molecules—millions of them—colliding and ricocheting in all directions. A single molecule might hit another close by, which hits another farther away, and in this way a movement in one place ripples invisibly into motion somewhere else. Language is like that. Each word is a molecule in a larger current—seemingly disconnected from distant words, yet bound to them through invisible chains of relationship.
Our words are part of an invisible map, laid out in the brain like trails on a mountainside. Every trail connects to others. You can go from the word wolf to howl to moon in a few steps, and the path makes sense. We can link thousands of such trails and cross the map any way we choose. That’s why we can say The wolf howled under the moon because it missed its pack, and someone else can follow us there.
Other animals also have words—signals encoding information. A prairie dog’s sharp chirp can indicate hawk overhead. A dolphin’s whistle can identify a particular friend. Wolves have over twenty distinct sounds they make to communicate. These are words in the sense that they point to something in the world. But they live on smaller maps. A few trails. A handful of landmarks. That is why context is so important to understanding how wolves interpret their smaller vocabulary.
Chaser the collie, Kanzi the bonobo, Koko the gorilla, and Alex the parrot each learned over a thousand human words, carrying language across the species divide and showing that, with patience, the distance between minds can be smaller than we imagine.
In a recent study of more than 260,000 button presses collected from 152 dogs using FluentPet, researchers found that many pets weren’t just hitting single buttons at random, but often paired two in sequence—“outside + potty”—to say something closer to a sentence. Nearly a third of all interactions were multi-button combinations, and analysis showed these pairings happened too often to be explained by chance or imitation alone. It was a small but telling bridge across the gap between human language and animal expression, proof that, given the right tools, a dog’s thought can stretch past a single word.
But what these remarkable animals have never achieved is combining their words into long, endlessly varied sentences.
Somewhere in our deep past, our brains (or one of our close relatives) crossed a threshold. Our vocabularies swelled, our connections multiplied, and the trails joined into a network so dense that you could walk it forever without retracing your steps. Scientists can model this “percolation point” in a computer: add enough words and enough links, and the network suddenly becomes a whole world. For English speaking children, that turning point comes when they have maybe two hundred and fifty words. That’s when their sentences leap from two words to three, four, and more—combinations no other animal makes on its own as far as we can tell today.
Inside the skull, this map is not built in one place. The brain’s “language network” lives mostly in the left frontal and temporal lobes, but there are outposts in the hippocampus, the cerebellum, and other corners. The hippocampus, long thought to be just a keeper of memory, also acts like a weather forecaster—predicting what words should come next and adjusting when they don’t. Work by Evelina Fedorenko and colleagues shows that these language circuits are separate from the systems we use for reasoning and other kinds of thought.
Artificial intelligence language models work in a similar way—though they are made of code, not neurons. They build what are called high-dimensional “latent spaces” where each word, phrase, and sentence is a point in a vast cloud. The geometry of this cloud—its distances, directions, and clusters—encodes meaning. Think of it like constellations in the night sky: each star is a word, and their positions relative to each other tell you which belong to the same figure. In the Goldstein et al. (2024) study, researchers showed that the brain’s semantic space in the inferior frontal gyrus shares geometric patterns with the latent space of a powerful AI model (GPT-2). Using “zero-shot” tests—where the model had to predict the brain’s activity for words it had never been trained on—they found the AI could accurately interpolate those brain patterns by relying on the geometry of relationships among other words. In other words, both brain and machine can jump to a new, unvisited point in semantic space simply by knowing the shape of the space around it.
That’s what “geometry” means here: the pattern of relationships. Just as in a map of mountain peaks, the distances and directions between points tell you where the next ridge lies, in a semantic map, the “angle” between wolf and howl and moon can tell you where night probably sits. Both brains and AI use these relationships to predict what should come next, to fill in blanks, and to weave meaning from context.
Simply because AI has a map for language does not mean it can think without human intervention. This distinction—between the maps for language and the machinery for thought—matters. It means that just because an animal doesn’t have human-style sentence building, it doesn’t mean its mind is simple. Thought is not locked inside language. People in deep coma or under anesthesia may be unable to speak or move, yet evidence suggests that some can still think—holding images, memories, or even abstract problems in their minds. The machinery for thought can run without the machinery for speech.
And if that can be true for us—silent but thinking—then perhaps it is true for the elk in the meadow, the raven in the wind, or the wolf on the ridge. They may not have our kind of words, but they may have their own mountains of thought. And if we accept that, we might choose to treat them as fellow travelers through their own unseen maps.
Latent Spaces in Brains and AI
From AI research:
-
In large language models (LLMs), words are represented as continuous vectors in a high-dimensional space, where geometry encodes meaning. This convergence between LLM embeddings and brain activity is explored in Goldstein et al. (2024), Alignment of brain embeddings and artificial contextual embeddings in natural language points to common geometric patterns — Nature Communications
-
Contextual embeddings (i.e., context-dependent word representations) outperform static ones in predicting brain responses — see Deciphering language processing in the human brain through LLM representations (Mar 2025)
From brain research:
-
Intracranial recordings in the inferior frontal gyrus (IFG) reveal that human “brain embeddings” for words share geometric structure with LLM embeddings — not just superficial correlations but deep vectoral alignment (Goldstein et al., 2024, same link as above).
-
The broader “Podcast” ECoG dataset supports modeling of neural activity during natural narrative comprehension using LLM features.
-
Research also suggests the hippocampus implements a vectorial code for semantics, leveraging geometry-rich representations — see Franch et al. (2025), A vectorial code for semantics in human hippocampus
Synthesis:
This combination of distributed vector coding and predictive geometry suggests semantic spaces in the brain are continuous, relational, and geometry-rich — enabling rapid access to related concepts via mechanisms such as hippocampal predictive coding.
The “Threshold” Problem — When Symbol Systems Become Open-Ended
Animal communication systems:
-
Tend to have small, context-bound vocabularies (e.g., alarm calls) and sparse networks with limited combinatorial links.
Humans:
-
Begin with sparse vocabularies that densify rapidly, often during the second year of life.
Developmental data:
-
Typically developing children produce ~50 words by 18 months and ~300 words by 24 months (Anglin 1989; Bates et al. 1988; Fenson et al.)
-
The “vocabulary spurt” around 16 months — once children have ~50 words — is well documented by Bloom, 2001, How Children Learn the Meanings of Words.
-
Expressive vocabulary growth to ~200–300 words by age 2 is also supported by speech-language development materials.
Percolation threshold assumption:
-
I adopt ~250 productive words as the threshold where the network gains enough connectivity for combinatorial productivity.
Mathematical Framing
Graph theory view:
-
Words = nodes; meaningful semantic/syntactic/pragmatic relationships = edges.
-
Percolation threshold = emergence of a giant component, where most nodes are connected via short paths.
Vector space view:
-
Words = points in an n-dimensional semantic space.
-
Similarity ↔ distance; transformations ↔ vector directions.
-
Threshold = density sufficient for systematic generalization, akin to analogy performance in AI.
Neurobiological alignment:
-
IFG and hippocampus may function as the brain’s geometry builder/navigator.
-
Hippocampal predictive coding helps in sequence prediction and mismatch detection.

Modelling Vocabulary Size and Combinatorial Structures
The following graphs were created in python code as a “toy” simulation of how a vocabulary network grows over time, and it produced two main graphs. Here’s what they mean in plain language:
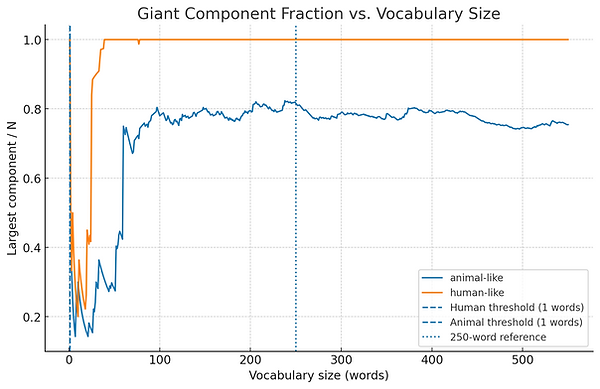
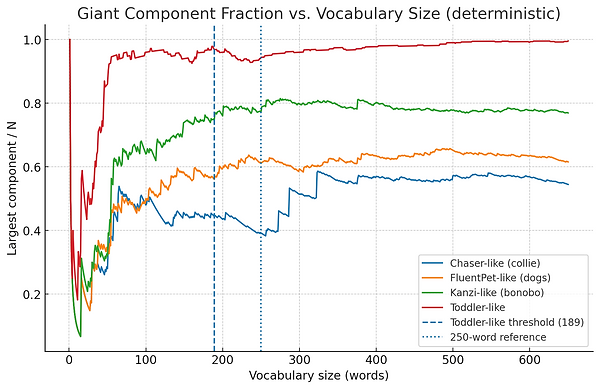
Graph 1. Giant Component Fraction vs. Vocabulary Size
-
Imagine each word a person (or animal) knows as a dot, and a line between two dots if those words are meaningfully connected (e.g., “dog” and “bark”).
-
In the beginning, you have a few small clusters of dots — little “islands” of connected words.
-
As vocabulary grows, more lines appear, and at some point, the small clusters merge into one big connected group (the giant component).
-
The first graph shows what fraction of all words belong to this giant connected group as vocabulary size increases.
-
A sharp jump means you’ve reached the percolation threshold — the point where almost all words are linked into a single network that can support lots of combinations.
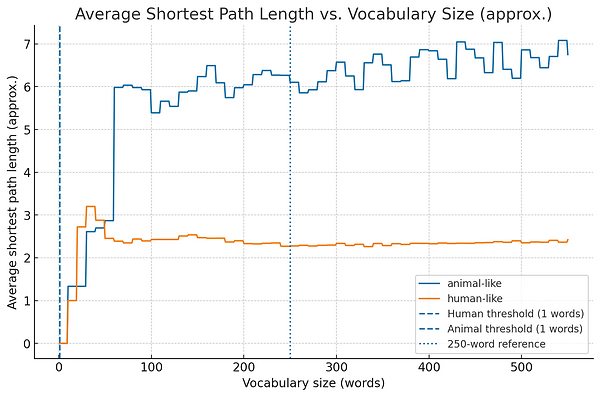
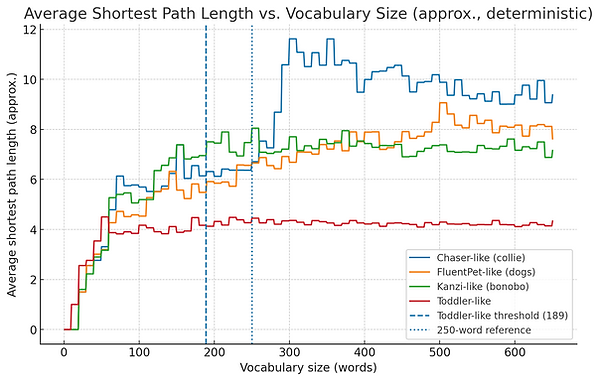
Graph 2. Average Shortest Path Length vs. Vocabulary Size
-
Once most words are in one network, you can measure how “far apart” they are — that is, how many steps it takes to get from one word to another through meaningful links.
-
At first, paths are long because the network is sparse and you have to hop through many intermediate words to get from one to another.
-
As more words and links are added, the average path length drops — meaning concepts are closer together, so you can connect ideas faster.
-
A sudden drop here usually happens right after the percolation threshold, when the network becomes much more efficient.
.png)

Source of the assumptions
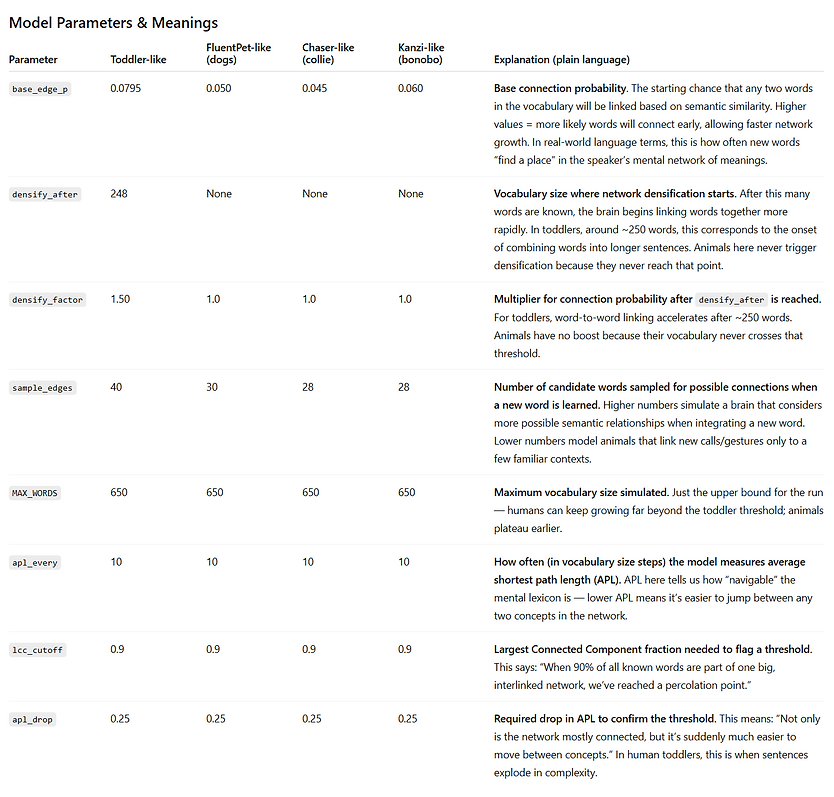
The code’s “animal-like” vs. “human-like” parameters are inspired by broad patterns in the literature, not exact species data. For example:
-
Vocabulary size limits — Most trained animals top out at dozens to a few hundred learned signals (e.g., Alex the parrot ~100 labels, Kanzi ~1,000 symbols but far lower productive variety).
-
Combinatorial use — Evidence that nonhuman species use very few multi-element combinations and often context-bound (e.g., no infinite recursion).
-
Acquisition rate — Humans’ word learning accelerates in early childhood (the “vocabulary spurt”), while animal learning remains roughly linear or plateaus.
These patterns come from studies on border collies (Pilley & Reid, 2011), bonobos (Savage-Rumbaugh et al., 1993), parrots (Pepperberg, 2007), and others — but our numbers are illustrative.
Why animals cap out at ~0.8 in the model
In our animal-like parameters:
-
Low base_edge_p means each new word has fewer links.
-
No densify_after event means there’s no tipping point to rapidly merge isolated clusters.
-
Semantic themes stay only loosely connected, so a portion of the vocabulary remains in small “islands,” never reaching the main component.
Reality check
Real-world animals don’t have measured “largest component” fractions for vocabulary graphs — because we don’t have that many mapped word–word link datasets for them.
This simulation is a conceptual model showing how those network properties could differ if you take into account known differences in:
-
vocabulary size ceilings
-
word acquisition rate
-
tendency to combine symbols
-
contextual restriction of signals
It’s a “what if” scenario, not a measured dataset.
Here are the knobs that drove that:
-
Base connection probability (base_edge_p)
-
Humans: higher (e.g., ~0.20) → new words more likely to link.
-
Animals: lower (e.g., ~0.06) → many words stay isolated or in tiny clusters.
-
-
Densification trigger (densify_after)
-
Humans: on (e.g., kicks in around ~150–220 words).
-
Animals: off.
-
Purpose: once vocab is big enough, humans get a jump in link probability—this pulls small clusters into one giant web.
-
-
Densification magnitude (densify_factor)
-
Humans: >1 (e.g., ~2.0–2.2×).
-
Animals: 1.0 (no change).
-
Effect: accelerates cross‑cluster “bridges” in humans.
-
-
Candidate neighbor sampling (sample_edges)
-
Humans: larger sample (e.g., 50–60) → more chances to form links.
-
Animals: smaller (e.g., 30–40) → fewer chances per new word.
-
-
Semantic clustering (latent space structure)
-
Same for both (e.g., ~6 themes; theme_spread≈0.65), but with low base_edge_p and no densification, animals rarely form cross‑theme bridges, so the graph stays fragmented and the giant component fraction plateaus < 1.0.
-
Variables that do not control giant‑component size directly (but help diagnostics): graph dimension of vectors, APL sampling cadence, and plotting refs—these don’t change connectivity dynamics meaningfully.
Net: Humans hit a phase transition (more links + a late densification boost) and roll most words into one component; animals never get the boost, so they top out with multiple medium components and a giant component < 1.0.
If we look at some data sets from actual animals (using different parameters for toddlers vs animals based on research), the graphs look like this.
.png)
.png)

Visualizing Vocabulary Size and Combinatorial Structures
The percolation web app visualizes how a growing vocabulary turns into a richly connected semantic network capable of supporting longer, more complex sentences. Each word is shown as a labeled node in a 3D space, and edges between nodes represent semantic connections determined by cosine similarity of their vector embeddings. As you adjust controls like vocabulary size, similarity threshold, and embedding dimensions, the network’s density and “giant component” size (the largest connected cluster of words) change in real time. When the giant component reaches a critical size—akin to a percolation threshold—paths between most words become short, making it easier to link multiple concepts together. This mirrors how, in human language development, reaching a certain vocabulary size (around 250 words for children) allows for spontaneous creation of novel 3-, 4-, and 5-word sentences without relying heavily on context.